

サイトを間違えて更新してしまい、手元にバックアップがない。
そんな緊急事態に対応できるようになります。
・間違えて違うサイトの情報をアップした
・別ディレクトリのindex.htmlをアップしてしまった
・必要なフォルダを消してしまった
こういった緊急事態が発生した際、作業前に取得しておいたバックアップを使用し、落ち着いて正しい情報を書き換えればよいのですが、万が一バックアップが残っていない場合は取り返しがつかない事態に陥ってしまいます。
サイトのソースをネットから取得し、復元する方法をお伝えします。
方法1:Googleのキャッシュを利用する
Googleが自動的にとっているキャッシュ(過去のサイト情報)にアクセスし、情報を復元することができます。
復元したいサイト(ページ)を検索で表示します
※例としてYahooを表示しています。

タイトルうえに表示されるパンくずの最後、「▼」マークをクリックします。
表示される、「キャッシュ」ボタンをクリックします。
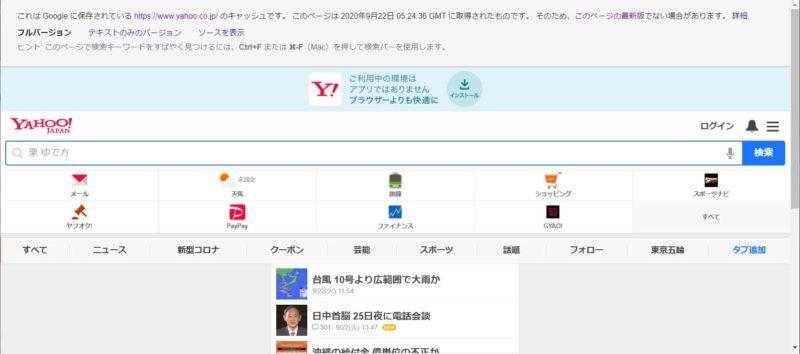
Googleが保存しているキャッシュの情報が表示されます。
ソースを表示・保存して復元を行いましょう。
方法2:Internet Archiveを利用する

ありとあらゆるサイトの過去の情報を定期的にアーカイブしているサイトです。(恐ろしいッ!)
使い方は超簡単です。
情報を入手したいサイトのURLを入力

いつの時点のサイトを閲覧するかを選びます。
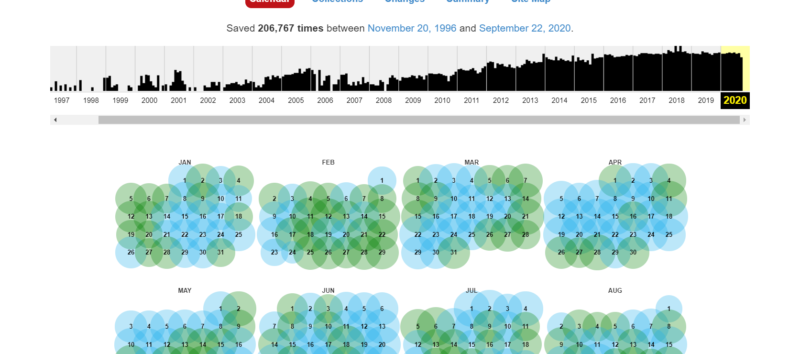
クリックするとその時点(yyyy-mm-dd hh-mm-ss)のサイトが表示されます。
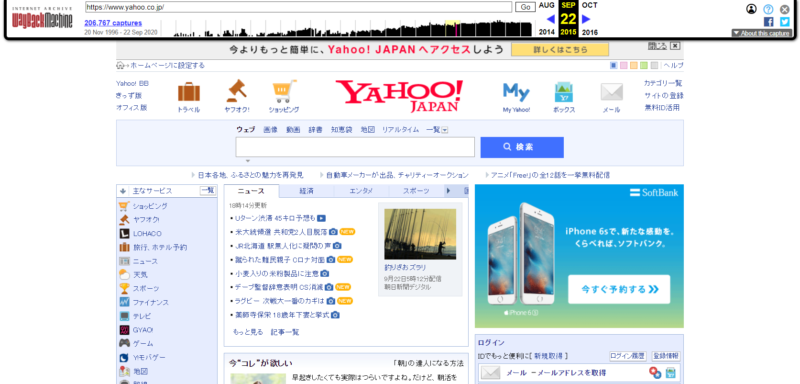
表示後は、上部にある黒いタイムラインの部分で、いつの時点かを自由に変更できます。

表示した情報ソースを取得
表示したページの情報は、ある程度通常のサイトと同じように操作が可能です。サイトの復元をするのであれば、ソースの情報を表示してコードを取得しましょう。
おまけ:Internet Archiveのその他、有効活用方法
競合サイトの改善内容やパフォーマンスを調査する際に利用
変更前の過去情報をInternet Archiveから引っ張ってくることで、競合サイトがサイトの更新を行った際に、調整内容をじっくり見比べることができます。
競合サイトが特定の時期に行っていたキャンペーンを知る
例えば、昨年の秋キャンペーンをライバルたちがどのように集客していたか。
などをのぞき見することができます。
まとめ
以下の方法で、過去サイトの情報を取得することができます。
方法1:Googleのキャッシュを利用する
方法2:Internet Archiveを利用する
最近だとギット管理を行っている場合が多いので、致命的なケースは起こりにくいですが、いざというときに知っておくと便利なテクニックです。必要に応じて活用してください。
サイトをアップする際は、
細心の注意を払ったうえで作業を行いましょう。

